Two-Dimensional Batch Linear Programming on the GPU
An efficient algorithm for solving multiple linear programs on the GPU.
Journal of Parallel and Distributed Computing - April 2019 (Published)
https://doi.org/10.1016/j.jpdc.2019.01.001
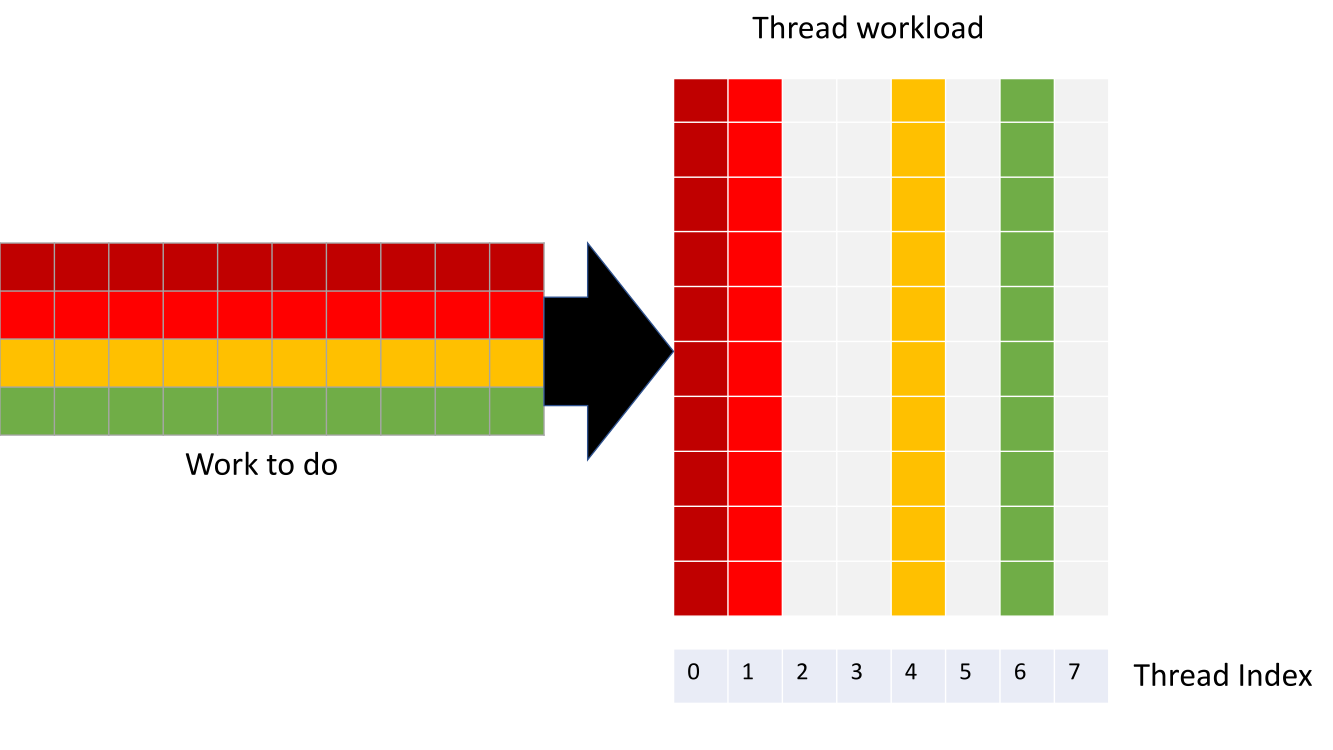
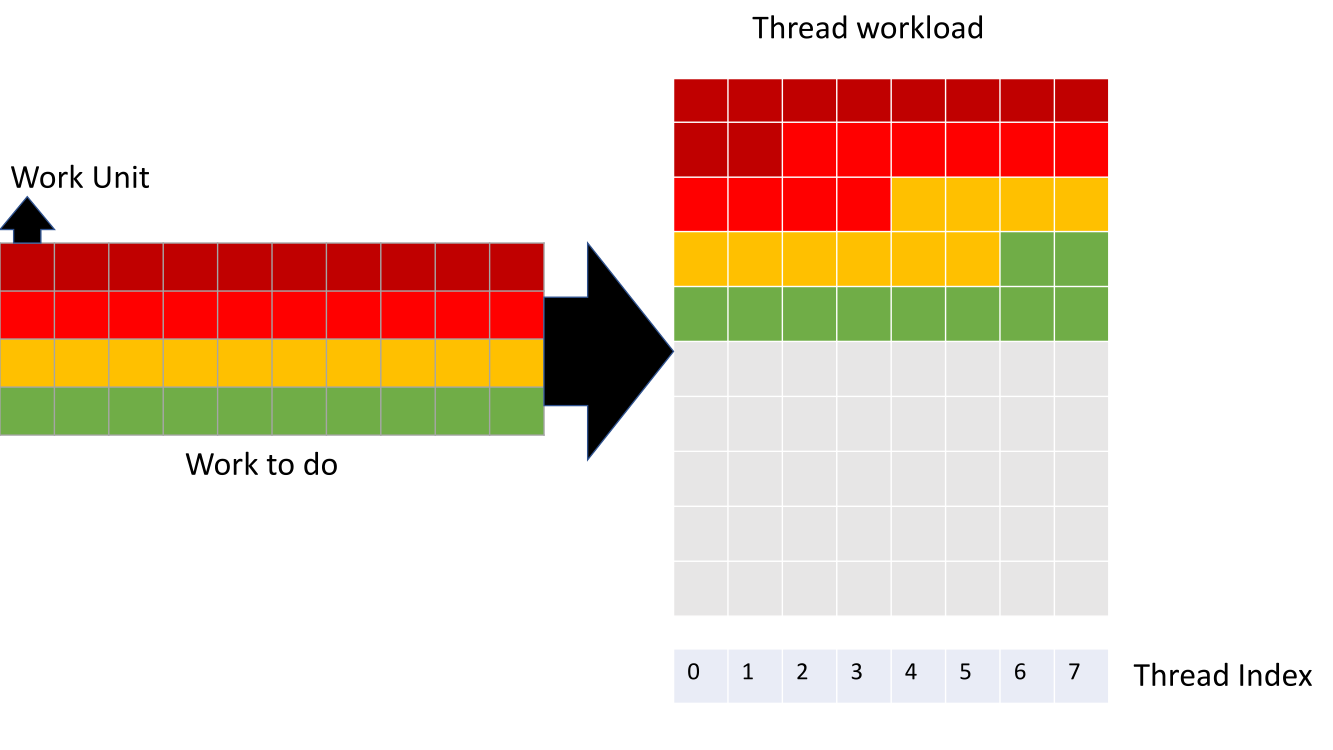
Implementation of “Work Units” - smallest common work load that the linear program can be composed of. Above: a naive implementation that fails to utilise some of the threads within a GPU warp. Below: distributing work units evenly across GPU threads to more fully utilise the device